
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- 단일 회선 #물리적 다중화 #주파수
- VLAN #망분리 #보안강화 #월패드보안
- 오류제어 #잉여비트 #FEC #ARQ #실시간성 #에너지효율
- 서버 비전송 #비대칭키 기반 #전자서명 검증 #불충분한 정보 #공개키 표준 #분리 인증
- 중복투자 방지 #자원효율성 제고 #공동구축 #중복방지 #비용분담 #필수설비 연계
- 5G #광섬유 #무유도 특성 #전력선 #인프라
- 구조 #모드분산 #사용파장 #사용광원 #전송거리 #비용
- 분리발주 #특허 #하자 #긴급 #안보
- 경제성 확보 #유지보수 효율화 #분기장치 #전원 필요 #AON #PON #저전력 #저비용
- 주파수 효율화 #장거리 전송 #왜곡 보상 #위상 #편파 #간섭수신 #LO(기준광) #90도 하이브리드 #DSP #고감도수신 #색분산 #400G/800G
- 양자컴퓨터 공격 #키분배(QKD) #데이터암호화(PQC) #물리 #수학 #중첩 #복잡성 #인프라 #확장성
- 시간 #파장 #효율성 극대화
- 메타물질 #음영지역 한계 #타겟 조향 #위상 제어 #진폭 제어 #음영해소 #조향 최적화
- 보안한계 #내외부 위협 #명시적 검증 #최소권한부여 #침해가정 #PDP #세분화 #IAM #MFA #SDP
- CTU #예측 #양자화
- 전력 손실 #일체형 #피딩로스 #빔포밍 #MIMO #케이블 최소화
- OTU #투명성 #FEC
- IPTV #전용망 #OTT #범용망 #ABR #CDN
- 공사비 산정 기준 #단위공종별 인력
- 제어 #탐지 #차단 #인라인 #미러링 #DPI
- 광케이블 의무화 #주거/업무용 #2코어 이상
- 오류 정정 #샤논 한계 # 잉여비트 #컨벌루션 #터보 #LDPC #샤논 #비터비 알고리즘
- 암호화 #협박 #백업 #격리 #대역폭 #분산대응
- 사용주파수 #목적 #야기우다 #패치안테나 #파라볼릭 #지향성
- 송신기 #급전선 #안테나 #손실 #임피던스 매칭 #선로정수
- O-DU #RIC
- Payload #OPU #ODU
- 노동력의양 #재료의양 #단위당복합단가 #일위대가 #원가산정 체계 #순공사비
- 송수신 공유 #Tx #Rx #BPF #FDD #격리도 #S파라미터
- O-CU
Archives
- Today
- Total
Creative Thinking Warehouse To be Rich
허프만 코딩(Huffman Coding) 본문
**허프만 코딩(Huffman Coding)**의 이해는 단순히 '트리 그리기'를 배우는 것이 아니라, '불평등의 미학' 즉, **"자주 나타나는 것에는 적은 자원을, 드물게 나타나는 것에는 많은 자원을 배분한다"**는 비대칭적 최적화의 관점에서 출발해야 합니다.
1. 허프만 코딩의 최상위 원리: "빈도에 따른 차등 대우"
이 토픽의 출발점은 **"모든 글자를 똑같은 길이(예: 8비트)로 표현하는 것이 과연 효율적인가?"**라는 질문입니다.
- 기본 상황: 기존의 고정 길이 부호(Fixed-length code)는 'A'든 'Z'든 똑같은 비트 수를 씁니다. 하지만 실제 데이터에서 'A'는 100번 나오고 'Z'는 1번 나옵니다.
- 본질: 많이 쓰이는 데이터에는 아주 짧은 이름(코드)을 붙여주고, 어쩌다 한 번 나오는 데이터에는 긴 이름을 붙여주는 **가변 길이 부호화(Variable-length coding)**입니다.
- 통찰: 모든 곳에 자원을 골고루 분산하는 대신, '영향력이 큰 곳(고빈도)'에 레버리지를 집중하여 전체적인 비용(평균 비트 수)을 획기적으로 낮추는 지능적 전략입니다.
2. 어디서부터 이해를 시작해야 할까? (3단계 핵심 알고리즘)
복잡한 수식 이전에 **'구조적 탄생'**의 원리를 파악하세요.
① 확률의 오름차순 정렬: "낮은 가치부터 묶기"
- 기본: 발생 확률이 가장 낮은 두 데이터를 찾습니다.
- 이해: 가장 힘이 약한(확률이 낮은) 것들부터 하나로 묶어 올라가는 Bottom-up 방식입니다.
② 이진 트리 형성: "선택의 지도 그리기"
- 기본: 두 데이터를 합쳐 하나의 노드를 만들고, 이 과정을 데이터가 하나만 남을 때까지 반복합니다.
- 이해: 위로 올라갈수록 확률의 합이 커집니다. 마지막에는 거대한 하나의 줄기(루트)가 형성됩니다.
③ 코드 할당: "왼쪽은 0, 오른쪽은 1"
- 기본: 루트에서 각 데이터까지 내려가며 길을 따라 숫자를 부여합니다.
- 이해: 자주 나오는 녀석은 루트와 가까워 코드가 짧고(예: 0), 드물게 나오는 녀석은 깊숙이 숨어 있어 코드가 깁니다(예: 1101).
3. 사고(What, Why, How, So what) 기반 답안 매칭
| 질문 | 답안 목차 | 핵심 서술 내용 |
| Why | 1. 개요 | 무손실 압축을 통해 정보의 엔트로피 한계에 도달하고 전송/저장 효율을 극대화하기 위함 |
| What | 2. 기술 개념 | 통계적 빈도수를 기반으로 한 가변 길이 부호화(VLC) 및 접두 부호(Prefix Code) 기술 |
| How | 3. 구성 절차 | 심볼 정렬 → 트리 생성 → 코드 할당으로 이어지는 알고리즘 도식화 |
| Attributes | 4. 주요 특징 | 무손실 압축, 접두어 특성(즉시 복호화 가능), 최적 부호화(Optimal) |
| So what | 5. 활용 및 동향 | JPEG, MP3, ZIP 등 현대 모든 압축 기술의 핵심이며 AI 데이터 경량화에 응용 |
💡 구글 시트 정리를 위한 한 줄 정리
- A열(토픽): 허프만 코딩 (Huffman Coding)
- B열(개요): 데이터의 발생 확률에 따라 빈도가 높은 심볼에는 짧은 부호를, 낮은 심볼에는 긴 부호를 할당하는 최적의 무손실 압축 기법.
- L열(키워드): 가.변.길.이.최.적.화 (Entropy, Binary Tree, Prefix-free, Lossless)
**"획일화된 규칙(고정 길이)을 버리고, 실질적인 영향력(확률)에 따라 자원을 차등 배분하여 시스템 전체의 효율을 임계점까지 끌어올리는 것"**이 허프만 코딩의 본질입니다.
1. 개요
- 정보원의 통계적 빈도수를 기반으로 발생 확률이 높은 심볼에는 짧은 부호를, 낮은 심볼에는 긴 부호를 할당하는 가변 길이 부호화(VLC) 방식임.
- 데이터의 중복성을 제거하여 평균 부호 길이를 정보원 엔트로피(Entropy) 한계치에 근접시키는 최적의 무손실 압축 기술임.
2. 기술 개념
- 핵심 원리: 확률적 분포에 따른 비대칭적 비트 할당. 전체 부호어의 평균 길이를 최소화하여 전송 및 저장 효율 극대화.
- 접두 부호(Prefix-free Code): 어떤 부호어도 다른 부호어의 앞부분(Prefix)과 일치하지 않도록 설계하여, 별도의 구분자 없이 즉시 복호화(Instantaneous Decoding) 가능.
- 압축 성능: 각 심볼의 발생 확률이 P_i일 때, 부호의 길이 L_i \approx -\log_2 P_i$가 되도록 구성하여 엔트로피 $H(X)$에 도달함.
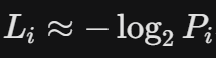
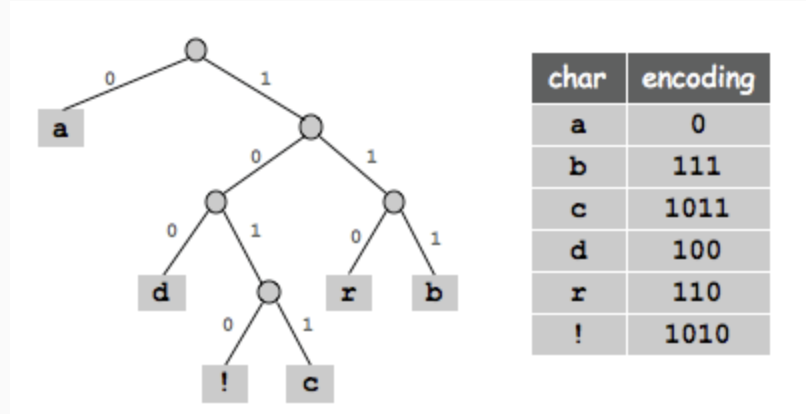
3. 알고리즘 구성 절차 및 트리 구조
가. 구성 절차 설명
- 확률 정렬: 모든 심볼을 발생 확률의 오름차순으로 나열함.
- 트리 생성(Bottom-up): 가장 낮은 확률을 가진 두 노드를 선택하여 합치고, 상위 노드에 확률의 합을 기록함. (단일 루트 노드가 남을 때까지 반복)
- 코드 할당: 생성된 이진 트리에서 상위 노드로부터 가지를 따라 내려가며 좌측 가지에는 '0', 우측 가지에는 '1'을 부여함.
나. 트리 구조의 특징
- 리프 노드(Leaf Node): 실제 데이터 심볼은 트리의 끝부분에만 위치함 (접두사 조건 만족).
- 경로 최적화: 루트 노드에서 가까울수록 고빈도 심볼이며, 부호 길이가 짧아짐.

4. 특징 및 기술적 장단점
| 구분 | 주요 특징 | 장점 및 단점 |
| 압축 방식 | 무손실 압축 (Lossless) | 장점: 원본 데이터의 100% 복원 보장 |
| 부호 길이 | 가변 길이 부호 (VLC) | 장점: 통계적 중복성 제거로 전송 효율 극대화 |
| 복호화 | 즉시 복호화 가능 | 장점: 수신과 동시에 실시간 해석 가능 (유일 복호성) |
| 통계 의존성 | 확률 분포 사전 파악 필수 | 단점: 데이터마다 확률 정보(Table)를 함께 전달해야 함 |
| 효율성 | 엔트로피에 근접한 최적성 | 단점: 확률이 $2^{-n}$ 꼴이 아닐 경우 효율 저하 발생 |
5. 활용 및 기술동향
가. 주요 활용 분야
- 정지영상/동영상 압축: JPEG, MPEG, H.264/AVC의 최종 단계에서 엔트로피 코딩으로 사용.
- 파일 압축: ZIP(Deflate 알고리즘), GZIP, PKZIP 등 범용 데이터 압축의 핵심 모듈.
- 오디오 코덱: MP3, AAC 등에서 양자화된 데이터의 추가 압축을 위해 적용.
나. 최신 기술동향 (2026년 기준)
- 산술 부호화(Arithmetic Coding)와의 결합: 허프만 코딩의 단점인 '비트 단위 할당' 한계를 극복하기 위해 더 정교한 CABAC(Context-adaptive binary arithmetic coding)으로 진화하여 VVC(H.266) 등에 적용.
- Adaptive Huffman Coding: 데이터의 통계적 특성이 실시간으로 변하는 스트리밍 환경에서 확률 표를 동적으로 업데이트하는 적응형 방식 채택.
- AI 데이터 경량화: 거대 언어 모델(LLM) 및 에지 컴퓨팅 기기에서 모델 가중치를 압축하기 위한 하드웨어 가속 기반 허프만 코딩 연구 활발.
- 시맨틱 통신 최적화: 단순 빈도수를 넘어 메시지의 중요도(Semantic)에 따라 비트 할당 우선순위를 정하는 차세대 정보원 부호화 기술과 접목.
**"획일화된 질서(고정 길이)를 거부하고, 실질적인 영향력(확률)에 따라 자원을 차등 배분하여 시스템 전체의 효율을 임계점까지 끌어올리는 지적 설계"**가 허프만 코딩의 본질입니다.
'정보통신 엔지니어링 > [8] 통신이론' 카테고리의 다른 글
| CRC(Cyclic Redundancy Check, 순환 잉여 검사) (0) | 2026.02.16 |
|---|---|
| 엔트로피와 Prefix-Code (0) | 2026.02.16 |
| Source Coding과 Channel Coding (0) | 2026.02.16 |
| Eye Pattern Diagram (0) | 2026.02.15 |
| ISI (Inter Symbol Interference) (0) | 2026.02.15 |